在使用 Coding Agent 时,同时接入多个模型来源已经非常常见。不同模型厂商通常提供不同的套餐和按量付费方式;实际使用中,也可能会接入第三方中转站或自建中转站,并在中转站中配置多个模型厂商账号,用于统一管理和负载分发。
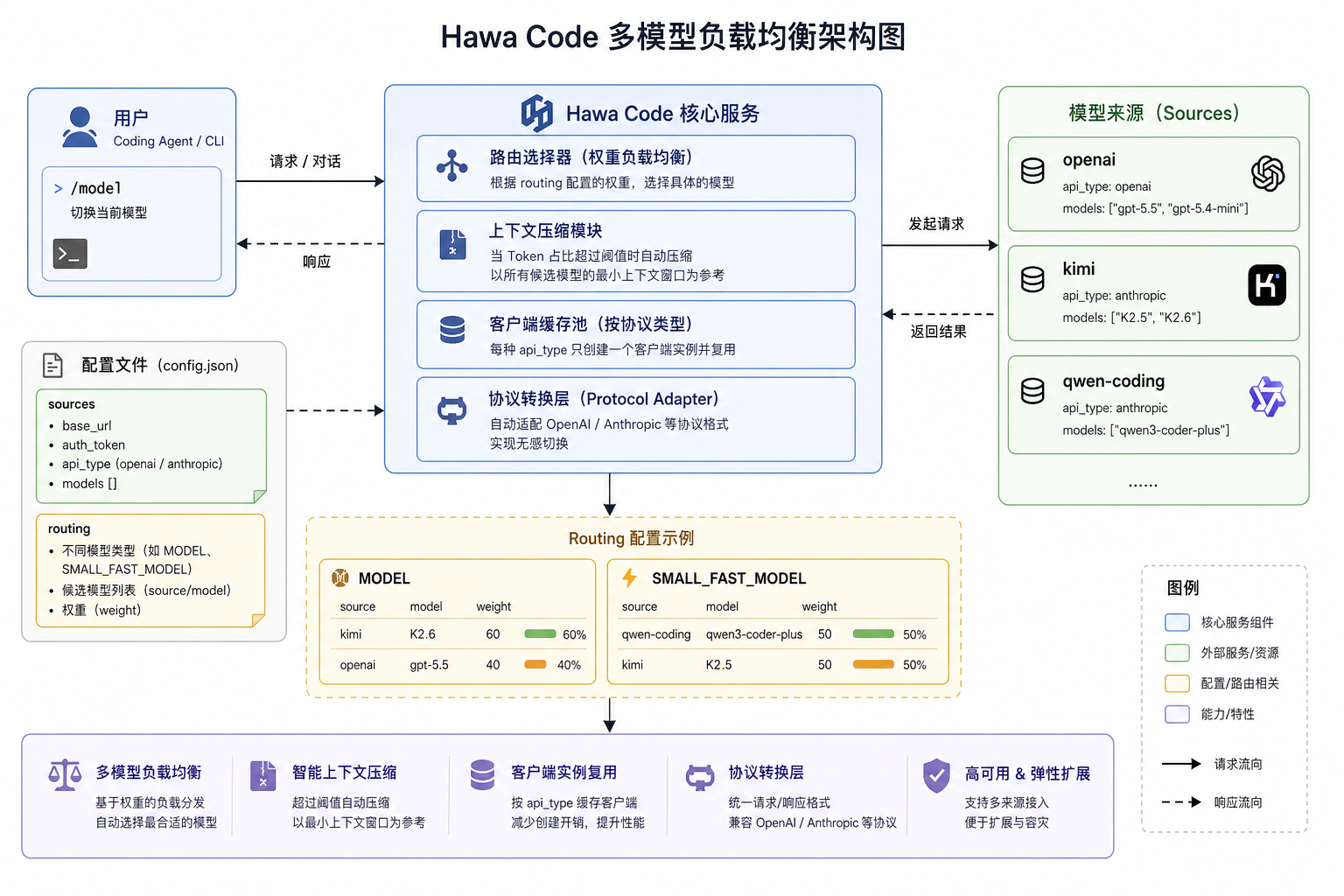
如果只有单一模型配置,当需要在不同模型之间切换时就会比较繁琐。针对这种场景,Hawa Code 提供了多模型负载能力:用户可以配置多个模型来源,由 Hawa Code 根据路由规则自动选择并访问不同的模型。
配置
sources 用于配置模型来源信息,包括访问地址、API Key 和协议类型。routing 用于配置 Hawa Code 实际使用的模型。每种模型类型都可以配置多个候选模型,并为它们设置不同权重,Hawa Code 会根据权重进行负载均衡访问。
{
"sources": {
"openai": {
"base_url": "https://api.openai.com/v1",
"auth_token": "{apikey}",
"api_type": "openai",
"models": ["gpt-5.5", "gpt-5.4-mini"]
},
"kimi": {
"base_url": "https://api.kimi.com/coding",
"auth_token": "{apikey}",
"api_type": "anthropic",
"models": ["K2.5", "K2.6"]
},
"qwen-coding": {
"base_url": "https://coding.dashscope.aliyuncs.com/apps/anthropic",
"auth_token": "{apikey}",
"api_type": "anthropic",
"models": ["qwen3-coder-plus"]
}
},
"routing": {
"MODEL": [
{ "source": "kimi", "model": "K2.6", "weight": 60 },
{ "source": "openai", "model": "gpt-5.5", "weight": 40 }
],
"SMALL_FAST_MODEL": [
{ "source": "qwen-coding", "model": "qwen3-coder-plus", "weight": 50 },
{ "source": "kimi", "model": "K2.5", "weight": 50 }
]
}
}
|
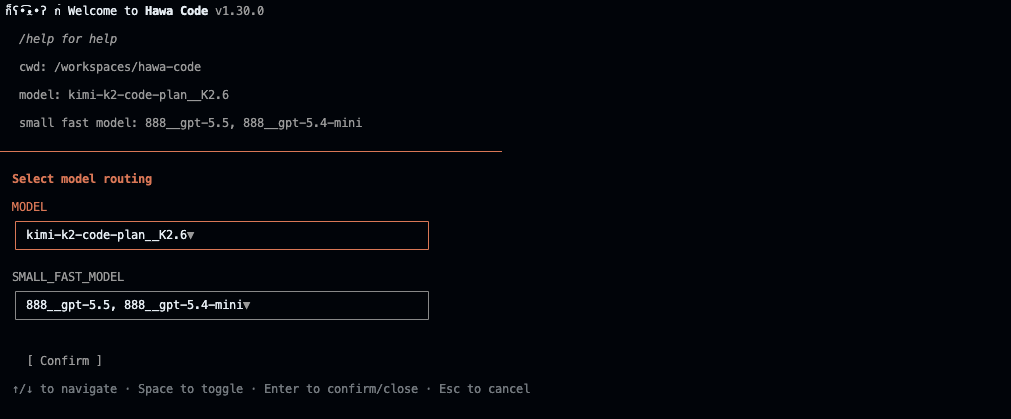
也可以直接在 CLI 终端中使用 /model 斜杠命令设置当前模型。
压缩
Hawa Code 会为每种模型设置默认的最大 Token 数量。当当前上下文的 Token 占比超过阈值后,Hawa Code 会自动压缩上下文。
如果配置了多个模型,Hawa Code 会以这些模型最大 Token 数量中的最小值作为压缩参考。因此,当多个模型的上下文窗口差距较大时,需要特别注意压缩触发时机,避免因为某个模型窗口较小而过早触发压缩。
缓存
对于每种模型类型,Hawa Code 只会创建一个客户端实例,并复用该实例发起请求,避免频繁创建客户端带来的额外开销。
协议转换层 (Protocol Adapter)
自动适配 OpenAI 或 Anthropic 等不同厂商的 API 协议格式,实现无感切换。